
This two part series will cover the what, when, and how of reliability in product development. The first part will focus on integrating reliability upstream in the development cycle with the second part focused on large scale testing to ensure a successful launch at mass production volume.
Introduction
The world of design, engineering, and product development is exciting as innovation needs to occur, challenges need to be overcome, and customers need to be delighted by the end-product. It’s wonderful! This cycle of innovation to product launches appeals to everyone and is at the crux of some of the world’s most valuable brands. But what else contributes to a brand’s long term value? How about overall quality? The staying power of these brands is not just that they quickly bring new ideas to market, but they bring new ideas to market with a craft and performance founded in a high quality experience.
For products to truly have a high quality experience, they have to be reliable. Customers rely on products to deliver their intended purpose and expect this usage to be consistent, reliable, and with no friction. Maybe this seems obvious. In this post, I plan to explain steps to help ensure that the integrity of a design is considered up front and not as a reaction to late-breaking issues.
Reliability Engineering
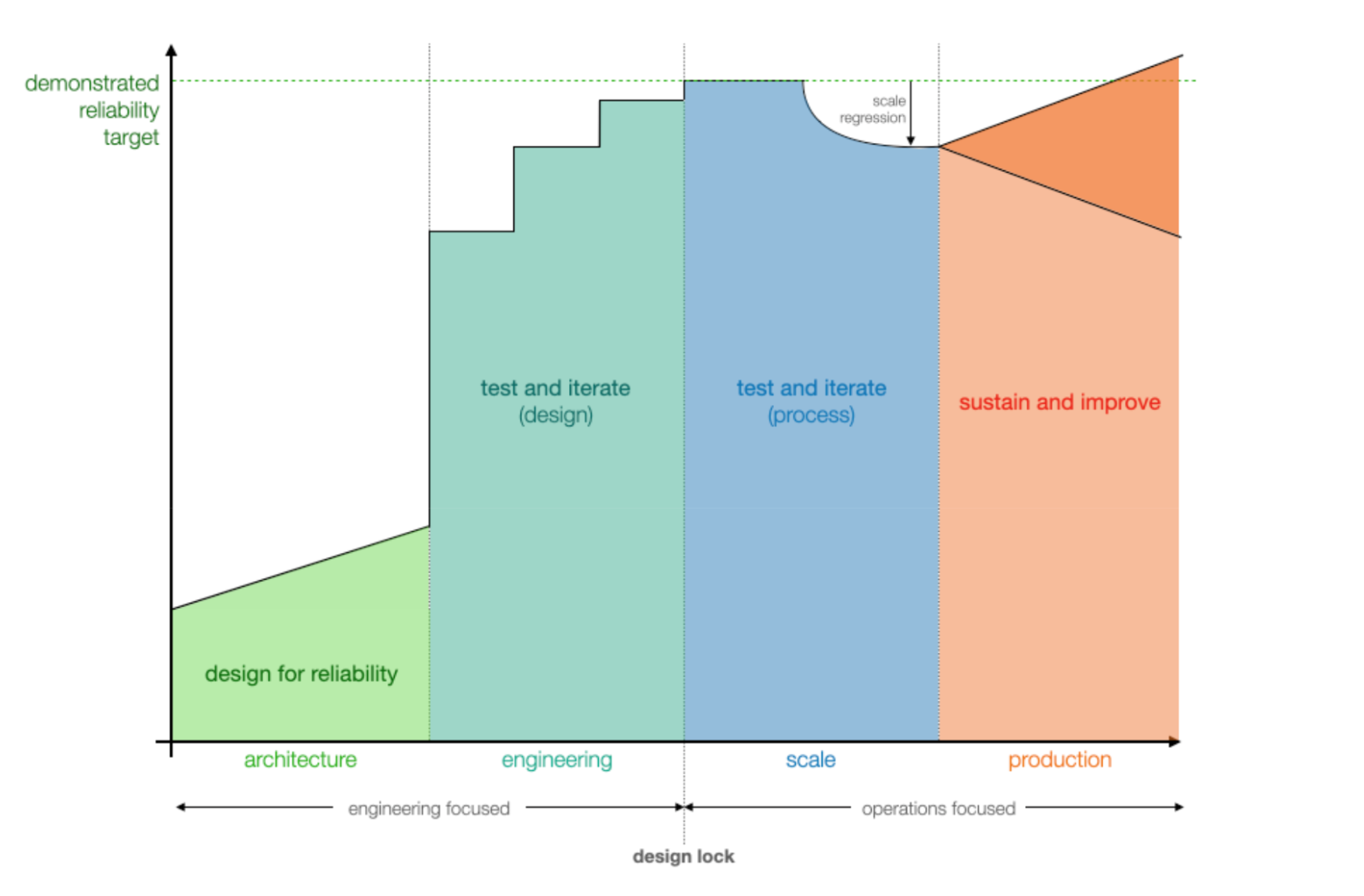
In hardware, reliability engineering is a discipline that partners across a company to ensure products can reliably operate within the expected use-cases and for a defined period of time. Reliability engineers' job is to identify, minimize, and mitigate risk. The goal for a reliability program is to demonstrate that the product meets a defined reliability target for a set confidence interval. Demonstrating a high-level of reliability performance for mass production scale is costly and takes time, so it is imperative to identify avenues to design reliability into your product or quickly identify risks during test-and-iterate cycles. I like to visualize this through architectural, engineering, scale, and production development cycles.
In architecture, the teams should be focused on identifying risks associated with foreseeable use and misuse usage scenarios. The teams should leverage design guidelines, customer knowledge, and engineering best practices to design against expected usage. The relative cost to the business to make changes in this phase is normalized to 1.
In engineering, the teams have developed a robust reliability test suite and are iterating on a PDCA (Plan Do Check Act) approach. Teams should be assessing risks for the core design of the product and making note of any process dependencies that require additional quality controls to be put in place. The relative cost to the business to make changes in this phase is ~10.
In scale, the teams are leveraging a qualification plan to scale the volume of the design. This qualification plan is assessing that large volume variation does not negatively affect the design’s demonstrated reliability. The relative cost to the business to make changes in this phase is ~30.
In production, the teams are using sustained quality control processes to minimize factory escapes and reliability failures. Given enough time and usage, the teams should also be leveraging in field telemetry and voice of the customer to make rolling changes and also to influence the next generation through extensive lessons learned initiatives. The relative cost to the business to make changes in this phase is largest.
Architecture Phase
The backbone of a good reliability program is understanding the diversity of your customer. Each person will use the product in their own unique way and with unique stresses. It is imperative to understand the diversity of stress that comes with a diverse customer population.
Understand Diversity of Your Customer
Knowing your end user is important to create a well received product. This is no different when it comes to understanding the risk and reliability of your product. For example, the US Department of Transportation published average driving miles for cohorts of age and sex. In this simple example, it is easy to see that designing an automobile for a 65+ year old female driver is different from designing an automobile for usage from a 35-54 year old male driver. The former drives ~4800 miles per year where the latter drives ~18900 miles per year. This is roughly a 4x difference in just “distance driven” usage and does not consider different driving styles, or other factors, associated with each cohort. When considering the reliability of a product, the best practice is to design for most of a diverse customer population. This entails representing 90% to 95% to 99% of the customer population in the specifications. For most end users, this may mean the product is ‘over designed’. But where one cohort of users can represent the average stress for a certain usage scenario, that same cohort of users may represent 99% stress for a completely different usage scenario. This is why a comprehensive understanding on usage stress and an approach founded in diversity is imperative to setting up a successful reliability program.
FMEAs
In the early stages of development, teams should dedicate time to performing an FMEA (Failure Modes and Effects Analysis). This exercise starts as a thought exercise to understand potential ways a product may fail, Failure Modes, and the resulting effects the failures would have on a user, Effects Analysis. Through the exercise, the teams will understand each risk on three vectors: Severity, Occurrence, and Detection or Control.
Severity : Ranging from a small nuisance to a catastrophic risk, such as a safety-related failure mode
Occurrence : How often the risk occurs
Detection/Control : Ability to keep the risk under control
The FMEA exercise is intended to be a living document of the most up-to-date knowledge on risks and their controls. In consumer electronics, FMEAs are predominantly used to assess design-based risks and process-based risks. Once potential failure modes and mechanisms have been understood, it is the engineering team's responsibility to prioritize, assess, and burn down these risks. As risks can be verification-related, reliability-related, quality-related, or any other dependency, the FMEA document needs to be a superset of all verification and validation functions assessing the product’s overall function and integrity.
Designing for Physics of Failure
Design Guidelines exist today in many industries and provide functional best practices on designing certain systems and subsystems. Design Guidelines mature generation over generation as the physics of the underlying mechanism become increasingly known. One example of such knowledge is transistor aging using Time Dependent Dielectric Breakdown (TDDB) modeling. Another example is material breakdown in the presence of chemicals, resulting in an Environmental Stress Cracking (ESC) mechanism. In the case of the ESC example, companies build repositories of knowledge on material robustness against factorial combinations of chemical type, chemical occurrence rates, amplitude of stress, and stress type. Companies who are versed in designing for reliability against ESC may use a test fixture called a Bergen Jig, which subjects material plaques to variable strain to understand critical strain threshold of materials when exposed to a range of chemicals. By understanding the holistic mechanical stress profiles and chemical exposure rates, a company can design out this cracking mechanism during the initial architecture phase. On the contrary, a company who is not familiar with the underlying mechanism will rely on many lengthy cycles of test-and-iterate to converge on an acceptable, though still risk inherent, final design. For a company to streamline demonstrated reliability, it is important to understand the physics of failure and design a product aware of these constraints.
This closes out Part 1 of understanding reliability within a product development process. In the upcoming Part 2, I will cover the Engineering to Production phases of the product life cycle where most companies currently focus integrity efforts.

Kevin Keeler is an accomplished product integrity leader and has focused his career on ensuring the future of innovative hardware is also reliable. Kevin believes products should be designed to be used and strives to enable his partners to build long lasting and world-class hardware. Kevin is energized by innovation and believes the impossible is possible.
Kevin is based in the bay area of California and enjoys staying active through sports, family adventures, or playing with his dog, Stella. For more information, please visit www.relfa.org.
More Insights



Interested in learning more about what it’s like to collaborate with Spanner?